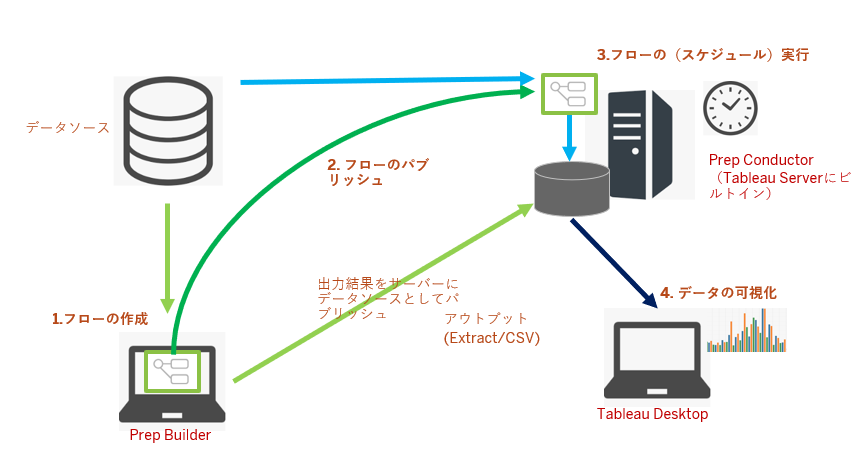
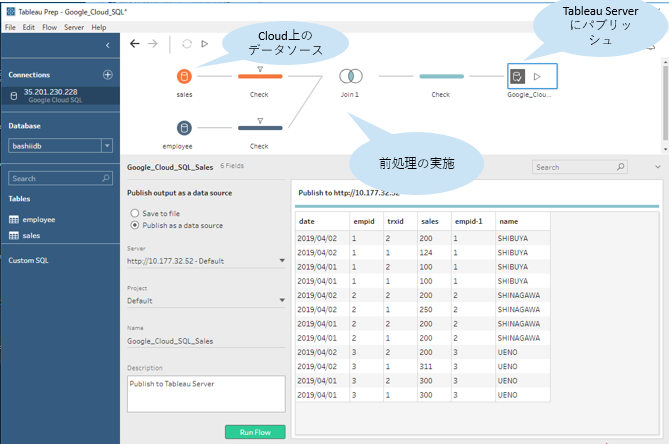
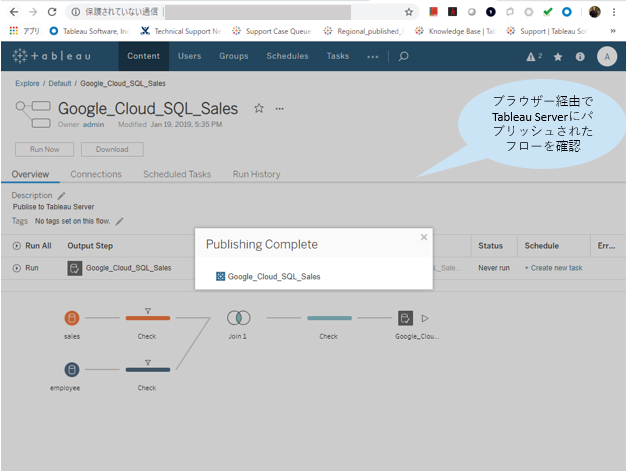
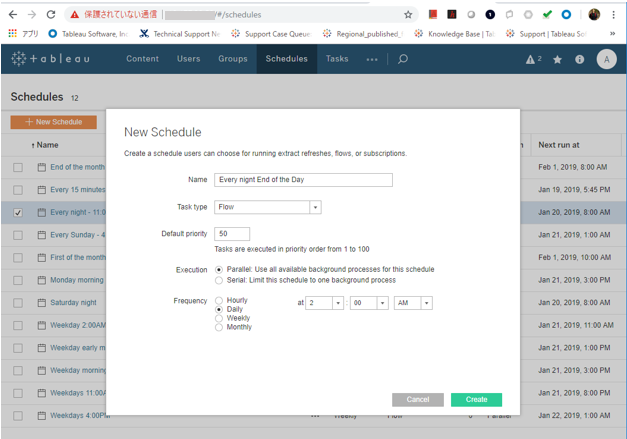
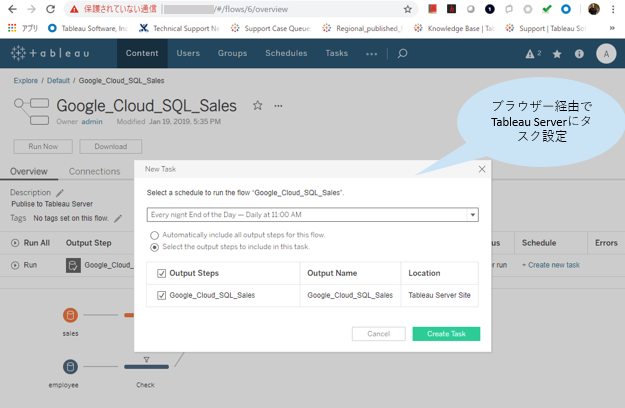
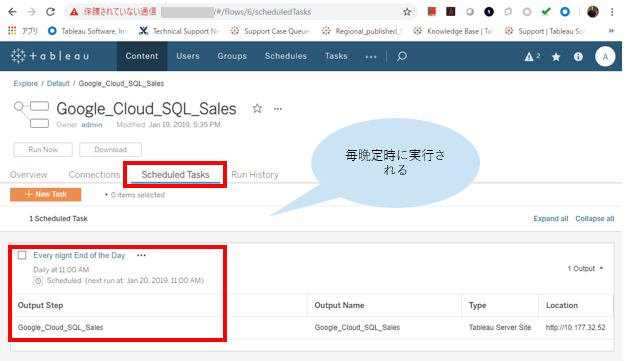
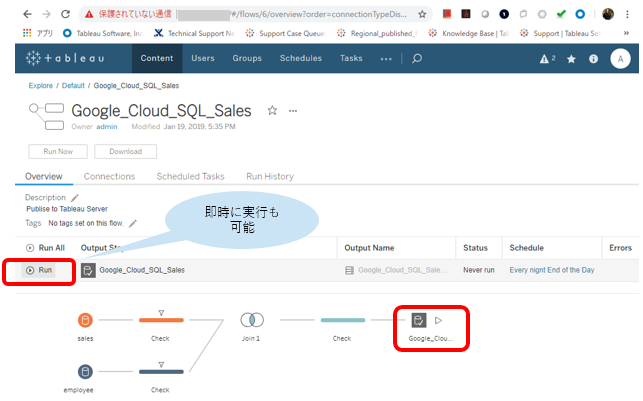
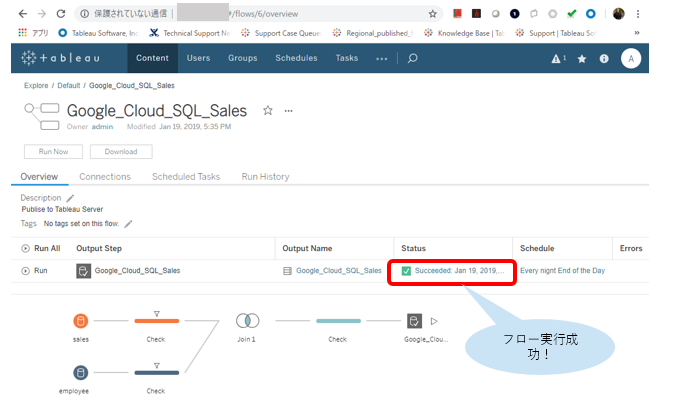
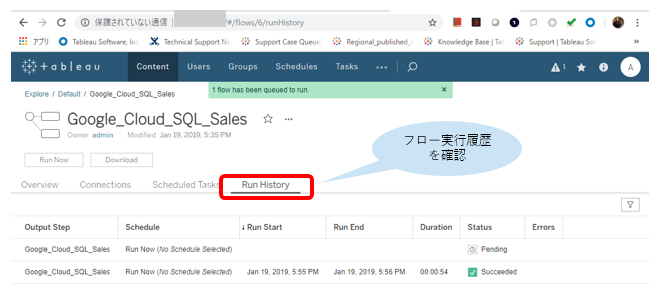
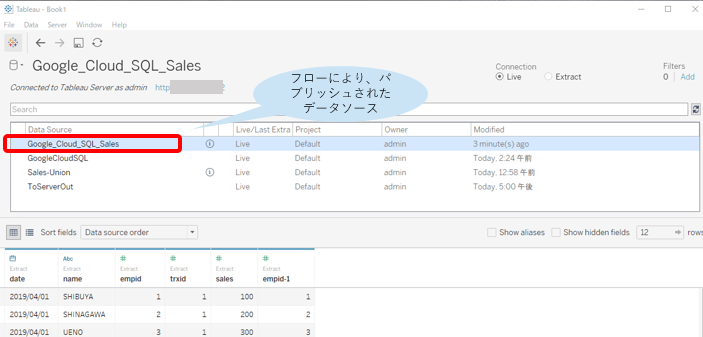
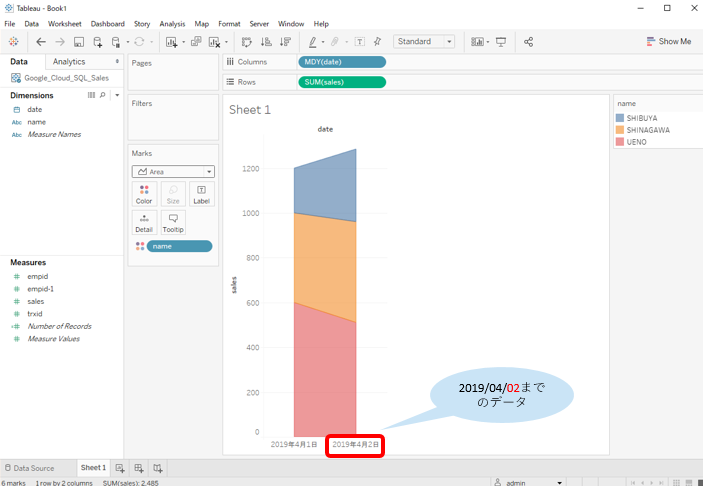
Tableau Bridge for Linuxやってみた
- クラウド→AWS
- OS→CentOS 7 with HVM
- スペック→m5.xlarge (4vCPU, 16GB)
- ストレージ→150GiB
- 検証したデータソース→MySQL、PostgreSQL、Redshift
- 作業PC→Macでのターミナル

の許可、およびTableau Cloudへのアクセス、つまりインターネットへのアウトバウンド許可は必須となってきます。
ssh -i [キーパス] ec2-user@[パブリックIP]
ssh -i [キーパス] centos@[内部IP]
これも言わずもがなでしょうか。もしここから・・・という場合はsshのコマンドの意味をインターネットでご確認ください。
アクセスできたら、ユーザーがcentosとなります。
(2) Dockerエンジンのインストール
もし、Dockerエンジンがすでにインストールされているイメージを利用してEC2を立ち上げた場合はここはスキップで構いません。
また、 Dockerがアップデートされたらここはうまくいかなくなる可能性もあるので、ホームページでチェックしたほうが無難となります。
最初にリポジトリを設定し、
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
Dockerをインストールします。
sudo yum install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
バージョンを指定する場合は、 yum list docker-ce --showduplicates | sort -r で確認して、docker-ceとdocker-ce-cliの後にバージョンを付けましょう。
そして、最後にDockerの開始とhello-worldイメージによるテストです。
sudo systemctl start docker
sudo docker run hello-world
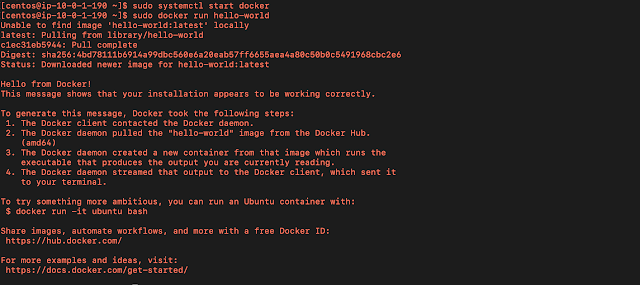
これにて完了です。では次にいきましょう。
(3) Bridgeコンテナイメージの作成
まずは、Tableau Bridgeのrpmパッケージが必要になるので、
sudo curl -OL [ダウンロードURL]
とかで持ってきましょう。ダウンロードのURLはこちらで確認できます。
続いて、作業ディレクトリを作っておき、
sudo mkdir Docker
cd Docker/
rpmファイルを移動させて、
sudo mv ./~/[Tableau Bridgeのファイル名].rpm ./
命令させるDockerfileを作ります。場所は任意です。
sudo touch Dockerfile
そして、Dockerfileには下記のような命令文をviで書きます。
# Centos 7 is the supported base image
FROM centos:7
# Update Packages
RUN yum -y update
# Copy the bridge RPM package, install it, then remove it from the image
COPY <Tableau Bridgeファイル名>.rpm/ <コンテナパス>
RUN ACCEPT_EULA=y yum install -y $(find . -name *.rpm) && rm -rf *.rpm
<コンテナパス>はコンテナ内でrpmファイルを置く場所なので/app/とかが一般的な気がします。
そしてRUN_ACCEPT_EULA=yはTableau利用規約に沿ったインストールという意味なので必ずつけましょう。
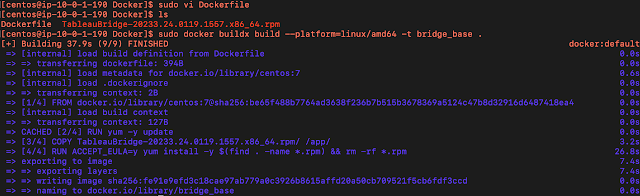
最後にイメージの構築です。
sudo docker buildx build --platform=linux/amd64 -t bridge_base .
うまくいけばここでいうと、bridge_baseというイメージが作成されます。
ここで2つのオプションを紹介します。
・構成設定ファイル
Tableau Bridgeの構成設定に関しては、TabBridgeClientConfiguration.txtファイルで管理しており、編集してコンテナをアップデートさせるよう設定する必要があります。
詳しくは割愛しますが、こちらに情報がまとまっています。
・ドライバー
Tableau BridgeではWindows版でもそうでしたが、MySQLやRedshiftへのアクセスにドライバーのインストールが必要になります。
ですので、例えば、ドライバーインストール用に別のDockerfileを用意して、ドライバーをインストールする命令文を記載し、
sudo touch Dockerfile_driver
sudo vi Dockerfile_driver
ここには↓書く(MySQLの場合)
# Using previously built bridge_base image
FROM bridge_base
COPY [ドライバーファイル名].rpm ./
RUN yum install -y [ドライバーファイル名].rpm
最後に先ほど作ったbridge_baseのイメージの上位レイヤーとしてイメージを作成すれば自動化できます。
sudo docker build -t bridge_final -f Dockerfile_driver .
これは結構マストの可能性高いですね。
(4) Tableau CloudのPAT作成
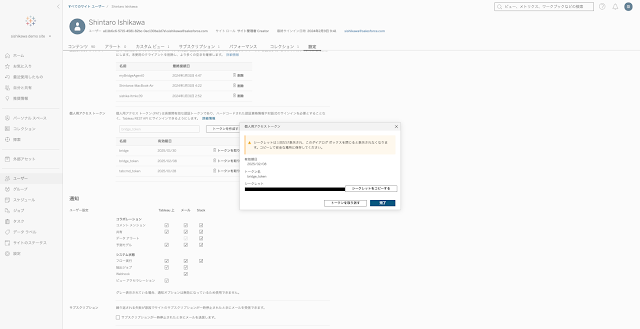
今回Tableau BridgeからTableau Cloudへ繋ぐ場合、PAT(パーソナルアクセストークン)が必要になりますので、あらかじめ作っておきましょう。
Tableau Cloudにログインをして、右上のユーザーアイコンから[マイアカウント設定]より、個人用アクセストークンを作成可能です。
トークン名とシークレットが必要になるので保管しましょう。
(5) Bridgeワーカー起動
これで最後です。
ただ、まずはロケールの設定ですね。特にMySQLではこれやってないとエラーになる事象は確認が取れています。
Docker側で設定を毎回するか、CentOS上で設定していまうかどちらかとなりますが、後者だと、
export LANG="en_US.utf8"
export LANGUAGE="en_US.utf8"
export LC_ALL="en_US.utf8"
を/etc/profileに追記する流れとなります。
続いて、Bridgeコンテナと対話型で繋がっていきましょう。
sudo docker container run -it bridge_final /bin/bas
でコンテナが開始され、rootでアクセスできます。
そして、先ほど作成したPAT情報をtxtファイルにJSON形式で書込み保存します。
cd /home/ touch MyTokenFile.txt
vi MyTokenFile.txt
ここでは、
{"トークン名": "シークレット"}
のような形で書き込みます。
そしてそして、セキュリティ強化のためのchmodです。
chmod 600 MyTokenFile.txt
では最後にワーカー起動です。
/opt/tableau/tableau_bridge/bin/TabBridgeClientWorker -e --patTokenId="[トークン名]" --userEmail="[ログインID]" --client="myBridgeAgent" --site=”[サイト名]" --patTokenFile="/home/MyTokenFile.txt"
TabBridgeClientWorkerのヘルプを見るのがいいですが、引数にTableau Cloudへの接続情報を入れないといけないので、間違いがないようコマンドを用意します。
無事に成功すると下記のようにService Startedとなり、終了です。

念のためTableau Cloudで左メニューの[設定]からBridgeタブに遷移すると、先ほど--clientにて設定したBridge名がコンピューター名として接続済みとなっていることが確認されました。

このページでは必要に応じて、プライベートネットワークの許可リスト(ドメイン/IP)とプールを構成して、Bridgeを割り当ててください。
また、MySQLなどDB/DWHで実際Tableau Cloudで接続確認すると、無事抽出が確認できました。
万が一できない場合は、プールの設定、もしくはネットワーク設定などを再度確認しましょう。
いかがでしたでしょうか。
私の個人的な感覚ですが、Linux慣れていたら、Windowsよりはるかに楽だと思います。また、Kubernetesで複数コンテナをオーケストレーションさせるよう構成を組んであげれば、コストパフォーマンスが著しく向上すると思います!
今後Kubernetesも挑戦していこうかと思いますので、その際は記事を投稿しようかな。
読んで頂きありがとうございました。
なお、Salesforceの公式とまではいきませんが、手順をまとめた資料がありますので、こちらもぜひご参照・ご活用くださいませ!
また、Tableauのヘルプページも参考になるかと思います。